― 検索と生成AIの“両方に読まれる”ための現実的アプローチ ―
Webサイトの情報を検索エンジンに正確に伝えるための構造化データは、「やった方がいいらしい」という認識で止まっている中小企業が少なくありません。Schema.orgの仕様は多岐にわたり、そのすべてを網羅しようとすると、結果的に複雑すぎて何も導入できない、あるいは導入してもすぐにメンテナンスが滞ってしまうというケースが散見されます。特にリソースが限られる中小企業にとって、この「全部盛り」のアプローチは現実的ではありません。
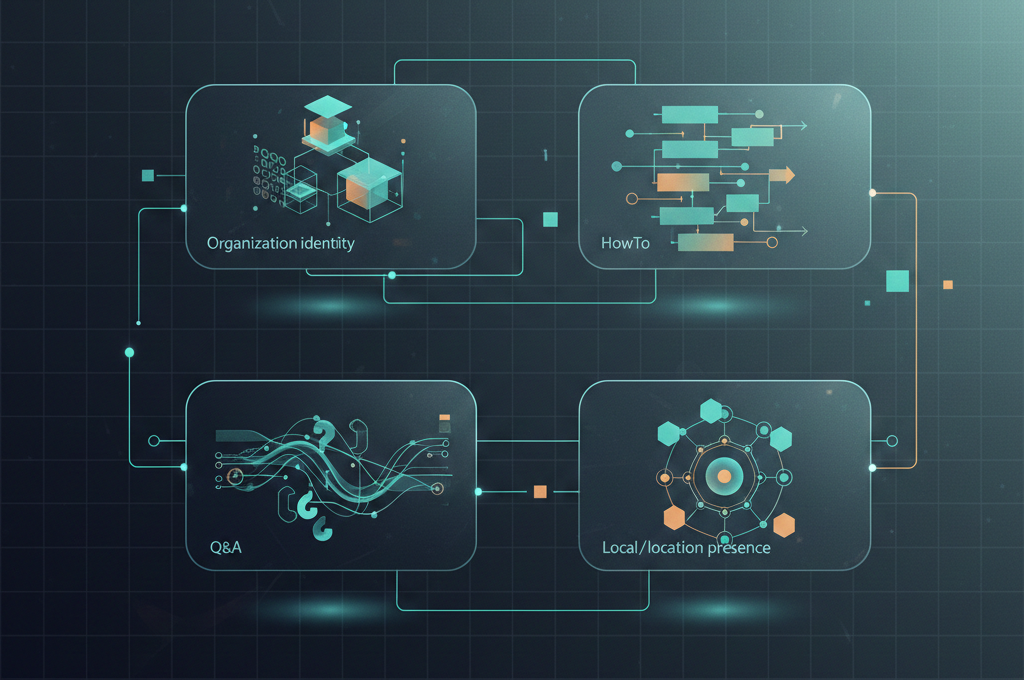
本記事では、LLMO(Large Language Model Optimization)時代において、検索エンジンと生成AIの双方に効率良く情報を伝えるために、最低限かつ効果的に運用できる構造化データ設計思想を解説します。具体的には、Organization、FAQ、HowTo、Localの4種類に絞り、これらを運用・自動化しやすい設計に組み込むための現実的なアプローチに集中します。ツールやプラグインの比較ではなく、持続可能なWeb運用を目指すための考え方を提供します。
なぜ「最小構成」の構造化データが重要なのか

構造化データは、Webページの内容を機械が理解しやすい形式で記述するメタデータです。しかし、多くの種類を欲張って「全部盛り」にすると、その管理コストが跳ね上がり、設計が失敗に終わる可能性が高まります。
全部盛りが失敗しやすい理由
構造化データは、ページ上のコンテンツと完全に一致している必要があります。例えば、商品の価格が変更されたにもかかわらず、構造化データ内の価格を更新し忘れると、検索エンジンはそれを本文と一致しない/誤解を招く構造化データは、リッチリザルト対象外になったり、品質上の問題として扱われ得ます。多種多様なスキーマを導入すればするほど、この整合性を保つための工数が増大し、リソースの制約が厳しい中小企業では運用が破綻しやすくなります。
中小企業のリソース制約
構造化データの設計、実装、そして最も重要な継続的な検証と保守には、専門的な知識と時間が必要です。中小企業が限られたリソースを最大限に活用するためには、効果の薄い、あるいはリッチリザルトの表示が不安定なスキーマに手を広げるのではなく、E-E-A-T(経験、専門性、権威性、信頼性)の補強や、LLMOに直結する引用されやすさに貢献する、核となる4種に絞り込むことが現実的かつ戦略的です。
生成AI・検索エンジン双方にとっての可読性
LLMO時代において、構造化データは従来の検索エンジンだけでなく、生成AIが回答を生成する際の引用元として機能します。AIは、構造化されたデータから、企業情報、Q&A、手順、所在地といったエンティティを迅速かつ正確に抽出できます。最小構成に絞ることで、AIに対して「このサイトの核となる情報はこれだ」と明確に伝えられ、ノイズが減り、双方にとっての可読性が向上します。
構造化データをAI自動化で扱う前提

構造化データは、一度設置したら終わりではありません。Webサイトの更新に合わせて常に最新の状態を保つ必要があります。この継続的な保守こそが、中小企業にとって最大の課題であり、生成AIの力を借りるべき領域です。
人手で書き続ける設計は破綻する
コンテンツが更新されるたびに、担当者が手動でJSON-LDコードを書き換える運用は、ヒューマンエラーのリスクが高く、必ず破綻します。特にブログ記事やFAQのようにコンテンツの追加・変更頻度が高いページでは、この問題は顕著です。構造化データは、CMSやデータベースと連携し、自動で生成・更新される設計を前提とすべきです。
構造化データは「一度作って終わり」ではない
構造化データは、Webサイトの「生きた情報」を反映し続ける必要があります。例えば、FAQの回答が変わった、HowToの手順が一つ増えた、営業時間や電話番号が変わったといった変更は、すべて構造化データにも反映されなければなりません。この「ページ内容との整合性の維持」こそが、運用における最重要課題です。
生成AIが向いている工程/向いていない工程
生成AIは、構造化データの**「作成」そのものよりも、「整理・保守」**の工程で真価を発揮します。
| 工程 | 生成AIの活用(向いている) | 人間の役割(向いていない) |
| 新規作成 | 既存のページコンテンツから、必要なプロパティ(質問、回答、手順など)を抽出・整理し、JSON-LDのテンプレートに流し込む。 | ゼロからJSON-LDのコードを生成し、ページに埋め込む。 |
| 整合性チェック | ページ上のテキストと、既存の構造化データの内容を比較し、不一致を検出する。 | 膨大なページを手動で目視チェックする。 |
| 保守・更新 | ページ更新時に、変更された箇所(例:FAQの回答)を特定し、構造化データ内の該当箇所を自動で書き換える。 | 変更のたびに手動でコードを修正する。 |
生成AIを「コードの自動生成ツール」としてではなく、「整合性維持のための自動チェック・更新アシスタント」として位置づけることが、持続可能な運用への鍵となります。
Organization|全ページ共通の基盤データ
Organizationスキーマは、企業や組織の基本情報を定義する、Webサイト全体の信頼性の基盤となるデータです。すべてのページに共通して設置すべき、最も優先度の高い構造化データと言えます。
Organizationが果たす役割
Organizationスキーマは、Googleのナレッジパネルやブランドプロフィールに表示される情報を補強し、検索エンジンや生成AIに対して「このWebサイトは誰によって運営されているのか」を明確に伝えます。これは、E-E-A-Tの要素である信頼性(Trustworthiness)を担保する上で不可欠な要素です。
最低限必要なプロパティ
中小企業が最小構成で運用する場合、以下のプロパティに絞り込むことを推奨します。
•name: 組織の正式名称
•url: 公式WebサイトのURL
•logo: 公式ロゴ画像のURL
•sameAs: 組織が運営する主要なソーシャルメディアアカウント(X、Facebook、LinkedInなど)のURL
特にsameAsプロパティは、Webサイト外の権威性(オーソリティ)を紐づける上で重要です。
自動生成・自動更新の考え方
Organizationデータは、通常、一度設定すれば頻繁に変わるものではありません。しかし、ロゴの変更や新しいソーシャルメディアアカウントの追加は発生します。このデータは、CMSの「サイト設定」のようなマスターデータとして一元管理し、全ページに自動でJSON-LDを挿入する仕組みを構築することが、最も効率的です。
FAQ|運用しながら増やせる構造化
FAQPageスキーマは、質問と回答のペアを構造化するもので、LLMO時代において非常に強力な効果を発揮します。
FAQがLLMOと相性が良い理由
FAQのリッチリザルト表示は、状況や分野によって出方が変わるため、表示を前提にせず“情報をQ&Aとして機械可読にする”目的で設計する。しかし、生成AIは、Webサイトのコンテンツを理解し、ユーザーの質問に対する回答を生成する際に、構造化されたQ&Aデータを優先的に参照する傾向があります。FAQPageは、AIが「この質問に対するこのサイトの公式見解はこれだ」と正確に引用するための、最も明確な指示書となるため、LLMO対策として非常に有効です。
FAQ化しやすいコンテンツの特徴
FAQ化すべきコンテンツは、以下の特徴を持つものです。
•ユーザーが頻繁に検索する具体的な疑問に対する簡潔な回答
•サービスや製品に関する誤解を解消するための情報
•企業の公式な見解やポリシーに関する情報
これらは、ユーザーサポートの履歴や、Webサイトの検索窓に入力されたキーワードから容易に抽出できます。
生成AIによるFAQ抽出・整理の考え方
生成AIは、既存の長文のコンテンツ(例:サービス紹介ページ、SEO/LLMOサービスの詳細はこちら)から、FAQの質問と回答のペアを自動で抽出・整理する工程に活用できます。
1.抽出: 記事の段落を読み込ませ、「この内容から想定されるユーザーの質問と、その回答を簡潔に抽出せよ」と指示する。
2.整理: 抽出されたQ&Aを、重複や表現の揺れがないかチェックし、最小限のプロパティ(QuestionのnameとAnswerのtext)に落とし込む。
この工程を自動化することで、コンテンツ作成と同時に構造化データも生成されるフローを構築できます。
HowTo|手順系コンテンツの整理
HowToスキーマは、特定のタスクを完了するための手順(ステップ)を構造化するものです。
HowToが向いている記事・向いていない記事
HowToスキーマは、明確な開始と終了があり、順番に実行されるべき手順を含むコンテンツに向いています。
•向いている例: 「〇〇ツールの設定方法」「〇〇の修理手順」「〇〇の申請方法」
•向いていない例: 「〇〇のメリット・デメリット」「〇〇の歴史」「〇〇に関する考察」
Google検索では How-to リッチリザルトは表示されなくなっています(そのため“表示目的”でのHowTo実装は狙いにくい)。一方で、サイト内の手順情報を機械可読に整理する用途としては有効です。生成AIが「手順」を回答する際に、構造化されたHowToデータは非常に参照しやすく、引用の精度を高めます。
最小限のHowTo設計とは
HowToスキーマで重要なのは、冗長な説明を避け、手順(step)と手順名(name)、そして**説明(text)**を明確に分けることです。各ステップは、ユーザーが実行すべき具体的なアクションを簡潔に記述する必要があります。
社内マニュアル・業務手順からの転用
中小企業には、既に整備された社内マニュアルや業務手順書が存在することが多いです。これらは、HowToスキーマの構造にそのまま転用できる、質の高いデータソースです。マニュアルをWebコンテンツ化する際に、同時にHowToスキーマを自動生成する仕組みを導入すれば、二重の手間を省くことができます。
Local|多拠点・地域ビジネスでの扱い
LocalBusinessスキーマは、物理的な店舗やサービス拠点を持つ中小企業にとって、地域検索(ローカルSEO)とLLMO対策の両面で不可欠なデータです。
Local構造化データが必要なケース
LocalBusinessスキーマは、以下の情報を提供することで、GoogleマップやAI検索における「近くの〇〇」といったクエリへの対応力を高めます。
•住所、電話番号、営業時間
•サービス提供エリア(areaServed)
•業種(@type)
多拠点ビジネスでの基本方針
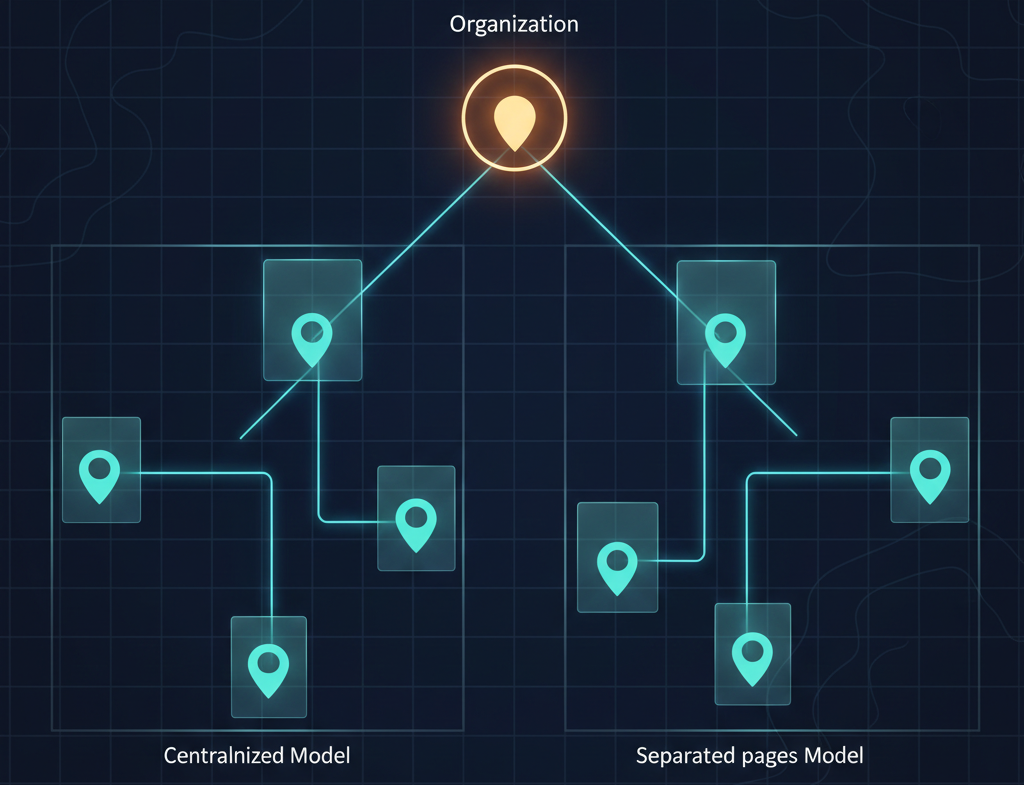
複数の拠点を持つビジネスの場合、すべての拠点を一つのWebサイトで扱うか、拠点ごとにページを分けるかによって設計が変わります。
•全拠点共通のデータ: サイト全体でOrganizationスキーマを使用し、その中に主要な連絡先情報を含める。
•拠点ごとのデータ: 各拠点ページ(例:店舗紹介ページ)にLocalBusinessスキーマを設置し、そのページ固有の住所、電話番号、営業時間を記述する。
拠点ごとに分ける/まとめる判断基準
LocalBusinessスキーマは、Googleビジネスプロフィール(GBP)の情報と完全に一致させる必要があります。
| 判断基準 | 拠点ごとにLocalBusinessを設置 | Organizationにまとめる |
| GBPの有無 | 拠点ごとにGBPがある場合 | 拠点ごとにGBPがない場合(本社情報のみ) |
| 情報の一意性 | 住所、電話番号、営業時間が異なる場合 | 住所、電話番号、営業時間がすべて共通の場合 |
| 検索意図 | 「〇〇店 営業時間」など、地域固有の検索に対応したい場合 | 企業全体としての信頼性を高めたい場合 |
多拠点ビジネスにおけるより詳細な戦略については、ローカルSEO×ローカルSEO×多拠点:店舗ページの正しい増やし方多拠点の解説記事はこちらを参照してください。
構造化データの検証と保守
構造化データは、実装後の検証と保守が最も重要です。これを怠ると、せっかくの努力が無駄になるだけでなく、検索エンジンからの評価を損なうリスクがあります。
検証を怠ると起きる問題
•リッチリザルトの非表示: 必須プロパティの欠落や、ページコンテンツとの不一致により、リッチリザルトの対象外となる。
•手動ペナルティ: 悪質なマークアップ(隠しテキスト、不適切なスキーマ利用など)と見なされ、手動ペナルティの対象となる。
•AIの誤引用: 古い情報や誤った情報がAIに引用され、ユーザーに誤った情報が伝わる。
定期チェックの考え方
構造化データの検証は、以下の2つの視点で行う必要があります。
1.構文チェック: GoogleのリッチリザルトテストやSchema Markup Validatorを使用して、JSON-LDの記述が正しいか、必須プロパティが揃っているかを確認する。
2.整合性チェック: 構造化データ内の情報(例:価格、住所、回答)が、ページ上の目視できるテキストと一致しているかを確認する。
自動化できる検証工程
構文チェックは、CI/CDパイプラインやCMSの機能に組み込むことで自動化が可能です。さらに、生成AIを活用すれば、整合性チェックも自動化できます。AIに「このページの構造化データと、本文の〇〇という箇所を比較し、不一致があれば報告せよ」というタスクを定期的に実行させることで、保守工数を大幅に削減できます。
よくある失敗例
最小構成の設計思想を実践する上で、避けるべき典型的な失敗例を挙げます。
•すべてのSchemaを入れようとして破綻する: 最初に述べた通り、リソースを分散させ、結果的にすべてのスキーマの保守が滞るパターンです。まずは4種に絞り、その運用が安定してから次のスキーマを検討すべきです。
•実際のページ内容と構造化データが乖離する: ページを更新した際に構造化データを更新し忘れる、あるいは構造化データにしか存在しない情報を記述する(隠しマークアップ)ことで、検索エンジンからの信頼を失います。
•拠点情報の重複・不整合: LocalBusinessスキーマとOrganizationスキーマで電話番号や住所が異なっていたり、Googleビジネスプロフィールと情報が一致していなかったりするケースです。地域ビジネスでは致命的な問題となります。
•AI生成コードをそのまま本番投入する: 生成AIはJSON-LDのコードを生成できますが、そのコードが常に最新の仕様やガイドラインに準拠しているとは限りません。必ずリッチリザルトテストで検証し、最小限のプロパティに絞り込むための人間のチェックが必要です。
まとめ
LLMO時代の構造化データ設計は、「量」ではなく「継続可能性」に焦点を当てるべきです。
•Organization / FAQ / HowTo / Local の4種に絞ることで、リソースを集中させ、持続可能な運用が回ります。
•生成AIは、構造化データ**“作成”よりも、“整理・保守”、特にページ内容との整合性チェック**で力を発揮します。
•この最小構成アプローチは、E-E-A-Tを補強し、検索エンジンと生成AIの双方に、貴社の情報を正確かつ効率的に伝えるための、最も現実的な戦略です。
CTA
JSON-LDスニペット4種(最小構成)
本記事で解説した設計思想に基づき、実務でそのまま使えるOrganization / FAQ / HowTo / Localの4種のJSON-LDスニペット(最小構成)を準備しました。これらは、自動生成・自動更新を前提とした設計となっており、貴社のWeb運用にすぐに組み込むことが可能です。
このスニペット集を活用し、LLMO時代に対応した構造化データ設計を今すぐ開始してください。
JSON-LDスニペット4種(最小構成)の設計思想
ここでは、本記事で推奨する4種の構造化データについて、自動生成・自動更新を前提とした最小限の設計と必須・推奨プロパティの考え方を記載します。
1. Organization(組織情報)
| 項目 | 必須/推奨 | 目的と設計思想 |
| @context | 必須 | https://schema.org を指定 。 |
| @type | 必須 | Organization を指定。 |
| name | 必須 | 組織の正式名称。CMSのサイト設定から自動取得。 |
| url | 必須 | 公式WebサイトのURL。CMSの基本設定から自動取得。 |
| logo | 推奨 | ロゴ画像のURLとサイズ(width, height)。CMSのロゴ設定から自動取得。 |
| sameAs | 推奨 | 主要なソーシャルメディアのURLリスト。E-E-A-Tの補強に不可欠。 |
| contactPoint | 推奨 | 代表電話番号や問い合わせメールアドレス。contactTypeを明記。 |
設計思想: サイト全体で一箇所のみ設置し、CMSのマスターデータと完全に連動させることで、更新漏れを防ぎます。
2. FAQPage(よくある質問)
| 項目 | 必須/推奨 | 目的と設計思想 |
| @context | 必須 | https://schema.org を指定 。 |
| @type | 必須 | FAQPage を指定。 |
| mainEntity | 必須 | 質問と回答のペア(QuestionとAnswer)の配列。 |
| Question (@type) | 必須 | 質問のエンティティ。 |
| name (in Question) | 必須 | 質問文全体。 |
| acceptedAnswer | 必須 | 質問に対する回答のエンティティ。 |
| Answer (@type) | 必須 | 回答のエンティティ。 |
| text (in Answer) | 必須 | 回答文全体。HTMLタグ(<p>, <ul>など)の使用が推奨されます。 |
設計思想: FAQセクションのコンテンツをAIが抽出し、この構造に自動でマッピングします。リッチリザルトよりも、生成AIの引用元としての精度向上を主目的とします。
3. HowTo(手順)
| 項目 | 必須/推奨 | 目的と設計思想 |
| @context | 必須 | https://schema.org を指定 。 |
| @type | 必須 | HowTo を指定。 |
| name | 必須 | 手順全体のタイトル。 |
| step | 必須 | 個々の手順(HowToStep)の配列。 |
| HowToStep (@type) | 必須 | 個々の手順のエンティティ。 |
| name (in HowToStep) | 必須 | 手順の簡潔なタイトル(例: 「ステップ1: ツールをダウンロード」)。 |
| text (in HowToStep) | 必須 | 手順の詳細な説明。 |
| totalTime | 推奨 | 全工程にかかる時間(ISO 8601形式)。 |
設計思想: 手順系コンテンツの各見出しと本文をCMS側で構造化し、このスキーマに自動出力します。手順の追加・削除が容易な設計とします。
4. LocalBusiness(地域ビジネス)
| 項目 | 必須/推奨 | 目的と設計思想 |
| @context | 必須 | https://schema.org を指定 。 |
| @type | 必須 | 該当する業種(例: LocalBusiness, Restaurant, Storeなど)。 |
| name | 必須 | 拠点名。 |
| address | 必須 | 住所(PostalAddress)。streetAddress, addressLocality, addressRegion, postalCodeを含める。 |
| telephone | 必須 | 拠点固有の電話番号。 |
| url | 推奨 | 拠点固有のページURL。 |
| openingHoursSpecification | 推奨 | 営業時間(OpeningHoursSpecification)。dayOfWeek, opens, closesを含める。 |
| geo | 推奨 | 緯度・経度(GeoCoordinates)。MEO対策に有効。 |
設計思想: Googleビジネスプロフィール(GBP)の情報と完全に一致させることが最優先です。多拠点の場合は、各拠点ページにのみ設置し、情報の一意性を保ちます。
参考文献
[1] [Google 検索セントラル: 構造化データの仕組みについて]
[2] [Google 検索セントラル: 組織(Organization)の構造化データ]
[3] [Google 検索セントラル: よくある質問(FAQPage)の構造化データ]
[4] [Google 検索セントラル: ローカル ビジネス(LocalBusiness)の構造化データ]